요즘 문서의 토픽(주제)를 모델링 하고 있는데, 이론을 이해하는게 중요해서 이론부터 구현까지 3편에 나눠서 연재할 예정이다. 첫번째는 토픽 모델링에 아주 유용한 방법인 잠재 디리클레 할당(LDA)에 대한 이론이고, 케빈 머피의 머신 러닝을 주로 참고하였다. 주로 27장에 관련 내용이 집중되어 있다. LDA와 관련된 이론도 차차 정리해볼 생각이다.
- 1편: 잠재 디리클레 할당(LDA)
- 2편: LDA를 이용한 토픽 모델링
- 3편: 토픽 모델링 시각화
정의
멀티누이 혼합에서, 모든 문서는 전역 분포 𝜋로부터 유도된 단일 토픽에 할당된다. LDA에서 모든 단어는 문서 지정 분포 𝜋i 로부터 유도된 자신의 토픽으로 할당된다. 문서가 단일 토픽보다는 전체 토픽 분포에 속하기 때문에 혼합재 혼합(admixture mixture) 또는 혼합 멤버십 모형(mixed membership model) 이라고 부른다.
응용 분야
문서 분석의 응용으로, 유전자학, 보건학, 사회과학 분석 등
기하학 해석
각 벡터 bk는 V 단어에 대한 분포를 정의하며, 각 k는 토픽으로 알려져 있다. 각 문서 벡터 𝜋i 는 K 토픽에 대한 분포를 정의한다. 따라서 토픽들의 혼합물로서 각 문서를 모형화 한다. 마찬가지로, 차원 줄임의 형태로서 LDA를 고려할 수 있다. V차원 심플렉스(벡터 xi를 카운트하는 일반화 문서)에서 포인트를 K 차원 심플렉스로 투영한다.
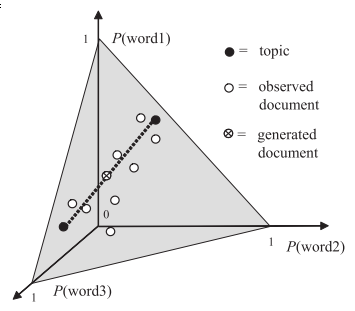
유클리드 공간보다 잠재 공간으로서 심플렉스를 사용하는 것은 심플렉스가 모호성을 처리할 수 있다는 이점이 있다. 특히 자연 언어는 단어가 자주 다중 의미를 가질 수 있기에 중요하다. 예를 들어, ‘play’는 동사(경기하다 또는 연주하다)로 간주되거나 명사(연극)일 수 있다. LDA에서는 여러개의 토픽이 주어지고, 각자 토픽에 맞는 단어 ‘play’를 만들 수 있다.
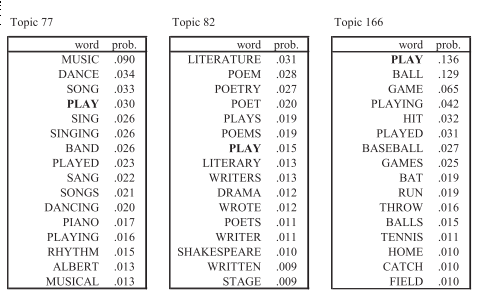
문서 안의 단어마다 어떤 토픽에 속하는지 추정할 수 있다. 단어만 따로 떼어본다면 단어가 의미하는 바를 아는게 어려울 수 있지만, 문서에서 다른 단어와 함께 본다면 애매하지 않다.
Xi가 주어질 때 문서에 대해 토픽 분포 𝜋i를 추정할 수 있다. 아래의 첫번째 문서는 음악과 연관된 다양한 단어가 있으며, 이것은 𝜋i 가 음악토픽에 대부분을 차지할 것이다. 첫번째 문서의 play는 음악적 단어로 해석되고, 두번째 문서는 연극의 의미로, 세번째는 스포츠의 의미이다. 𝜋i 가 잠재 변수이기에 정보다 문서 내의 단어 출현 확률사이에서 움직일수 있다. 따라서 전체 단어 집합(코퍼스)을 사용할 수 있도록 지역적인 모호성 해소가 가능해진다.
토픽의 비지도 발견
LDA의 주요 목적 중 하나는 대량의 문서나 코퍼스에서 토픽을 발견하는 것이다. 주의할 점은 토픽을 나누더라도, 토픽의 해석은 어렵다. 그래서 토픽을 해석하는 다양한 방법들이 있는데, 시각화를 통해 토픽의 해석을 도울 수 있다.
- 태그 표시(Ramage et al. 2009)

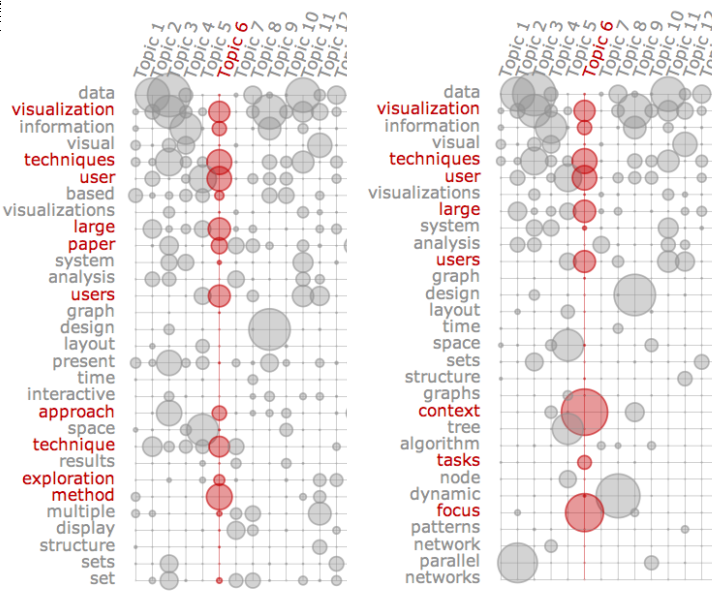
- 적합도(relevance)(Sievert et al. 2014)
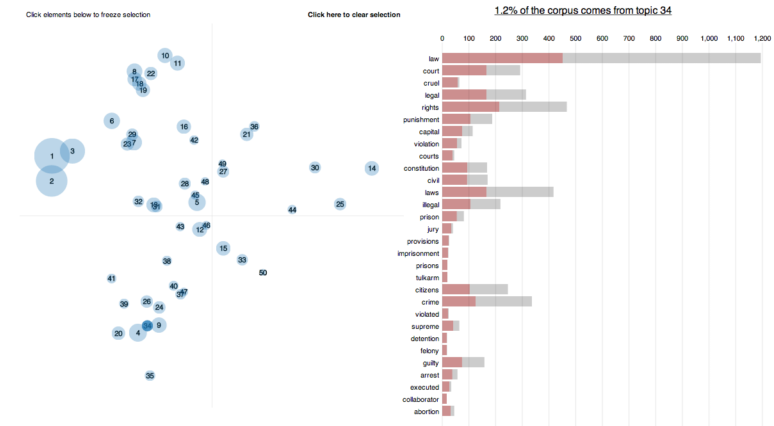
- 돌출도(saliency)(Chuang et al. 2012)
함께 볼 것
다항 PCA모형과 매우 유사하며, 범주형 PCA(Principal Component Analysis)와 GaP(Gamma-Poisson), NMF(Non-negative Matrix Factorization)와 밀접한 연관이 있다.
참고문서
-
Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. The MIT Press.
-
Sievert, C., & Shirley, K. (2014). LDAvis: A method for visualizing and interpreting topics. Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, 63–70. Retrieved from http://www.aclweb.org/anthology/W/W14/W14-3110
-
Chuang, J., Manning, C. D., & Heer, J. (2012). Termite : Visualization Techniques for Assessing Textual Topic Models. Proceedings of the International Working Conference on Advanced Visual Interfaces - AVI ‘12, 74. https://doi.org/10.1145/2254556.2254572