잠재 디리클레 할당 관련한 것들을 리뷰하고서 수많은 의료 명세서를 몇 개의 주제로 요약할 수 있겠다는 감이 생겼다. 그러나 사람들은 병원에 한번 가고 말지 않는다. 같은 질환으로 혹은 다른 질환으로 계속 병원에 간다. 그래서 시간 흐름에 따라 의료 데이터를 분석하려면 어떻게 해야할지 궁금했다. 건강 궤적이란 개념이 이 지점에서 나온다. 건강 궤적에 대한 다양한 정의가 있긴 한데, 여기서 말하는 것은 개인의 건강 정보가 시간에 따라 변화하는 과정을 통틀어서 말한다. 개인의 건강 궤적을 만들어 내고나면, 유사한 궤적끼리 묶어서 환자군을 만들 수 있다. 이런 내용을 모형화 한 점이 이 연구에서 재밌었던 부분이다. 그러나 마지막 결과 그래프가 별로였다. 군집별로 질병에 걸린 순서가 각기 다른데, 기울기 그래프에서는 전혀 보이지 않아서 해석하기 어려웠다.
문제
-
개인의 건강 궤적을 클러스터링 하기
-
건강 궤적이란 개인의 건강 정보가 시간에 따라 변화하는 과정을 통틀어 의미함
-
건강 정보에는 범주형 변수와 연속형 변수가 섞여있음, 특히 범주형 변수를 시계열로 표현하는 것과 그 시계열(궤적)을 클러스터링하는 것은 뾰족한 방법이 없음.
-
여기서 범주형 변수의 예는 심장병, 뇌졸중, 당뇨 등의 진단명
데이터셋
-
데이터셋 1: 45세 이상의 1,255 궤적 시뮬레이션 데이터
-
45 and Up Study 데이터, 호주의 뉴사우스웨일즈 주의 메디케어 데이터 중 표본추출한 데이터를 베이스라인으로 잡음
-
2-3년 주기의 설문에 동의한 참여자들은 뉴사우스웨일즈의 45세 이상 인구의 11%를 커버함
-
위 설문을 바탕으로 2년 주기의 260,000 개의 건강 궤적을 생성함.
-
그 중에 건강 정보가 복잡한(주로 동시이환/합병증 가진 사람들) 궤적들만 뽑아냄.
-
1,255 궤적은 다음 질병을 모두 포함-심장병, 뇌졸중, 당뇨, 비만, 흡연 상태
-
Features:
-
Specific health condition c (where c = H for heart disease, c = D for diabetes and c = S for stroke)
-
Smoking state(not/quit), BMI(normal, overweight)
-
-
-
데이터셋 2: 건강과 은퇴 설문에 대한 종적 연구로부터 추출한 268 궤적 데이터
-
미시건 대학, 1992년부터 27천명의 노년 인구의 다면적 상태(건강,재정,가족,직업 등)를 설문한 데이터
-
데이터 크기가 작고 궤적 길이가 짧은 것을 제외하고 호주의 데이터셋과 전반적으로 유사함
-
문제 해결 방법
-
은닉 마코프 모델(HMM)
-
왜 HMM을 사용했을까?
-
데이터 셋의 확률 분포가 어떨것이다.. 라는 가정 없이 하려고 함. 왜냐면 데이터 셋이 복잡하기 때문에 이런 가정을 두는 것이 무의미함
-
개인의 건강 궤적을 비슷한 것 끼리 묶는다면, 유사한 원인을 공유하는 사람끼지 묶어야 마땅하지만, 그 원인은 너무도 다양하고, 설문(관측가능한 데이터) 에서 드러나지 않음.
-
심장병, 뇌졸중과 같은 질병이나 흡연 여부는 우리가 관측 가능한 변수임
-
따라서 이런 변수의 발현 확률을 조건으로 특정 건강 궤적의 확률을 유도할 수 있음
-
-
건강 궤적을 클러스터링 하려면?
-
건강 궤적간의 유사도는 계산하는 방법도 없고, 어렵지만, 건강 궤적의 확률간의 차이는 계산할 수 있음
-
대칭 쿨백-라이블러 발산 함수를 이용하면 두 분포의 차이를 계산할 수 있음.
-
따라서 궤적들 사이의 거리를 계산할 수 있고, 유사한 궤적들끼리 묶을 수 있는 것임.
- 쿨백-라이블러는 비대칭 함수이기 때문에, D(A, B) != D(B, A)임. 그래서 이 논문은 D(A,B), D(B,A)를 합하여 평균을 사용했음. 그래서 대칭이라는 수식어가 붙음
-
-
궤적의 확률간의 차이를 계산하려면?
-
쿨백-라이블러 발산 함수를 사용하면 두 확률 사이의 차이를 계산할 수 있음. 그러나, 계산 시간이 너무 오래걸리고, 데이터 복잡도가 높을수록 더 어려움
-
몬테카를로 추정으로 값을 근사하는 방법이 한가지 대안인데, 이것도 어렵다고 함. (사용자가 확률 밀도 표본을 따로 뽑아야 해서라는데…잘 와닿지가 않음 ㅋㅋ)
-
그렇다고 샘플 딱 하나만 뽑아서 전체를 대표한다고 가정하는 것도 위험한 방법임.
-
이 논문은 그 중간 방법을 선택했음. (아직 이해 못했음ㅋ)
-
-

-
중간점 주변 분할-Partitioning Around Medoids (PAM)
-
쿨백-라이블러 발산 함수로 인해 궤적간 거리벡터가 나옴.
-
거리벡터를 입력으로 받는 클러스터링 알고리즘은 넘나 다양하고, 그 중에 PAM을 사용했음
-
PAM은 클러스터마다 중심점이 있고, 각 중심점 근처의 데이터 포인트 들의 차이를 최소화 하는 알고리즘임
-
최적의 클러스터 개수를 계산해 주지 않기 때문에, 사용자가 다양한 선택해야 함.
-
최적의 클러스터 개수를 검증하는 방법으로 실루엣 인덱스, 데이비스-볼딘 인덱스, 듄 인덱스를 사용함. 실루엣과 듄 인덱스는 높을수록, 데이비스-볼딘은 낮을 수록 좋음.
-
-
은닉 상태 변수의 개수 추정
-
Features의 특징은 곧 클러스터의 특징과 연결됨.
-
이 논문은 각 feature가 되도록 서로 연관되지 않아야 한다는 기준을 잡음. (왜일까??)
-
몇개의 은닉 상태 변수가 있어야 Features 의 조합 사이의 상관계수가 최소가 되는지 계산함. (잘 이해가 안됨)
-
그 결과 3개의 은닉 상태 변수가 적절하다고 결론 내림
-
결과
-
호주 데이터셋
-
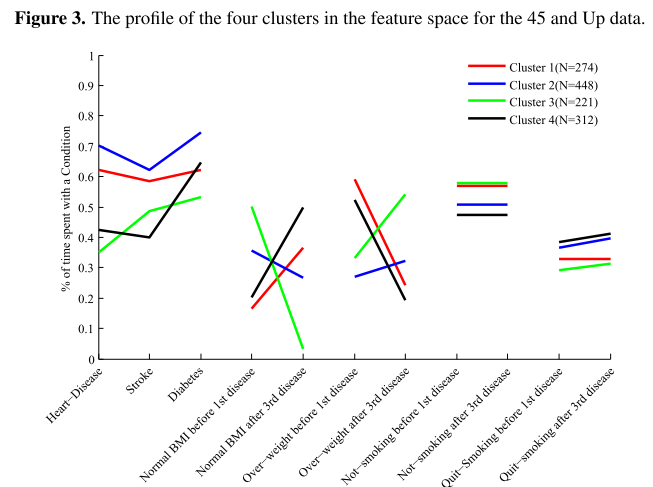
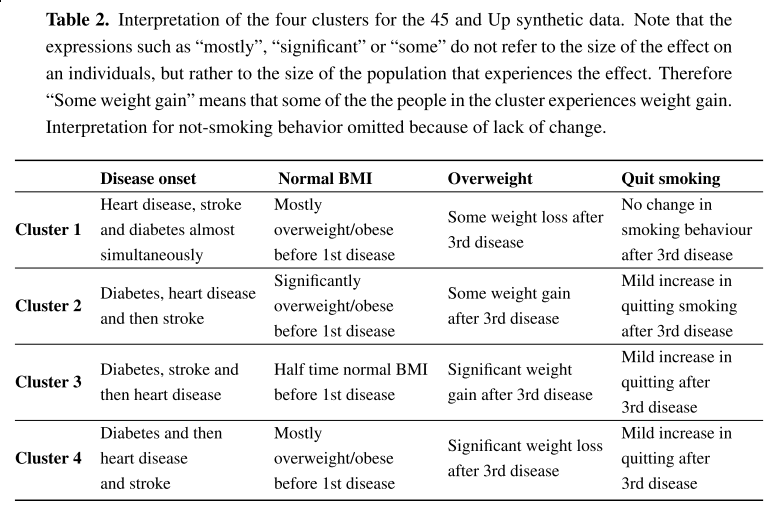
클러스터 4개가 최적
-
클러스터 4번
-
당뇨병 발병한 기간이 전체의 60%, 심장병, 뇌졸중은 전체의 40-45%
-
초기부터 당뇨가 진행되었고, 그 이후로 심장병과 뇌졸중이 심해짐
-
첫번째 질병(당뇨) 전에 BMI가 정상인 궤적은 20%, 즉 대부분이 과체중인 군
-
세번째 질병 후에 BMI가 정상인 궤적이 50%, 즉 절반의 사람들이 심장이나 뇌졸중 이후 체중감소를 겪었음
-
-
클러스터 1번
- 궤적의 60%에 당뇨병, 심장병, 뇌졸중이 고루 차지함
-
클러스터 3번
-
첫번째 질병(당뇨) 이전에 BMI가 정상인 궤적이 50%
-
세번째 질병(심장병) 이후에 과체중이 되는 궤적이 50%
-
-
참고 논문
- Ghassempour, S., Girosi, F., & Maeder, A. (2014). Clustering multivariate time series using Hidden Markov Models. International Journal of Environmental Research and Public Health, 11(3), 2741–63. https://doi.org/10.3390/ijerph110302741